tl;dr: We have a
new paper casting doubt on previous work on automatic theory of mind. Musings on open science and replication.
Do we automatically represent other people's perspective and beliefs, just by seeing them? Or is mind-reading effortful and slow? An influential paper by
Kovács, Téglás, and Endress (2010; I'll call them KTE) argued for the automaticity of mind-reading based on an ingenious and complex paradigm. The participant watched an event – a ball moving back and forth, sometimes going behind a screen – at the same time as another agent (a Smurf) watched part of the same event but sometimes missed critical details. So, for example, the Smurf might leave and not see the ball go behind the screen.
When participants were tested on whether the ball was
really behind the screen, they appeared to be faster when their beliefs lined up with the Smurf's. This experiment – and a followup with infants – gave apparently strong evidence for automaticity. Even though the Smurf was supposed to be completely "task-irrelevant" (see below), participants apparently couldn’t help "seeing the world through the Smurf’s eyes." They were slower to detect the ball, even when they themselves expected the ball, if the Smurf didn’t expect it to be there. (If this short description doesn't make everything clear, then take a look at our paper or KTE's original writeup. I found the paradigm quite hard to follow the first time I saw it.)
I was surprised and intrigued when I first read KTE's paper. I don't study theory of mind, but a lot of my research on language understanding intersects with this domain and I follow it closely. So a couple of years later, I added this finding to the list of projects to replicate for my graduate methods class (my class is based on the idea – originally from Rebecca Saxe – that
students learning experimental methods should reproduce a published finding). Desmond Ong, a grad student in my department, chose the project. I found out later that Rebecca had also added this paper to her project list.
One major obstacle to the project, though, was that KTE had repeatedly declined to share their materials – in direct conflict with the
Science editorial policy, which requires this kind of sharing. I knew that Jonathan Philips (Yale) and Andrew Surtees (Birmingham) had worked together to create an alternative stimulus set, so Desmond got connected with them and they generously shared their videos. Rebecca's group created their own Smurf videos from scratch. (Later in the project, we contacted KTE again and even asked the Science editors to intervene. After the intervention, KTE promised to get us the materials but never did. As a result, we still haven't run our experiments with their precise stimuli, something that is very disappointing from the perspective of really making sure we understand their findings, though I would stress that because of the congruence between the two new stimulus sets in our paper, we think the conclusions are likely to be robust across low-level variations.)
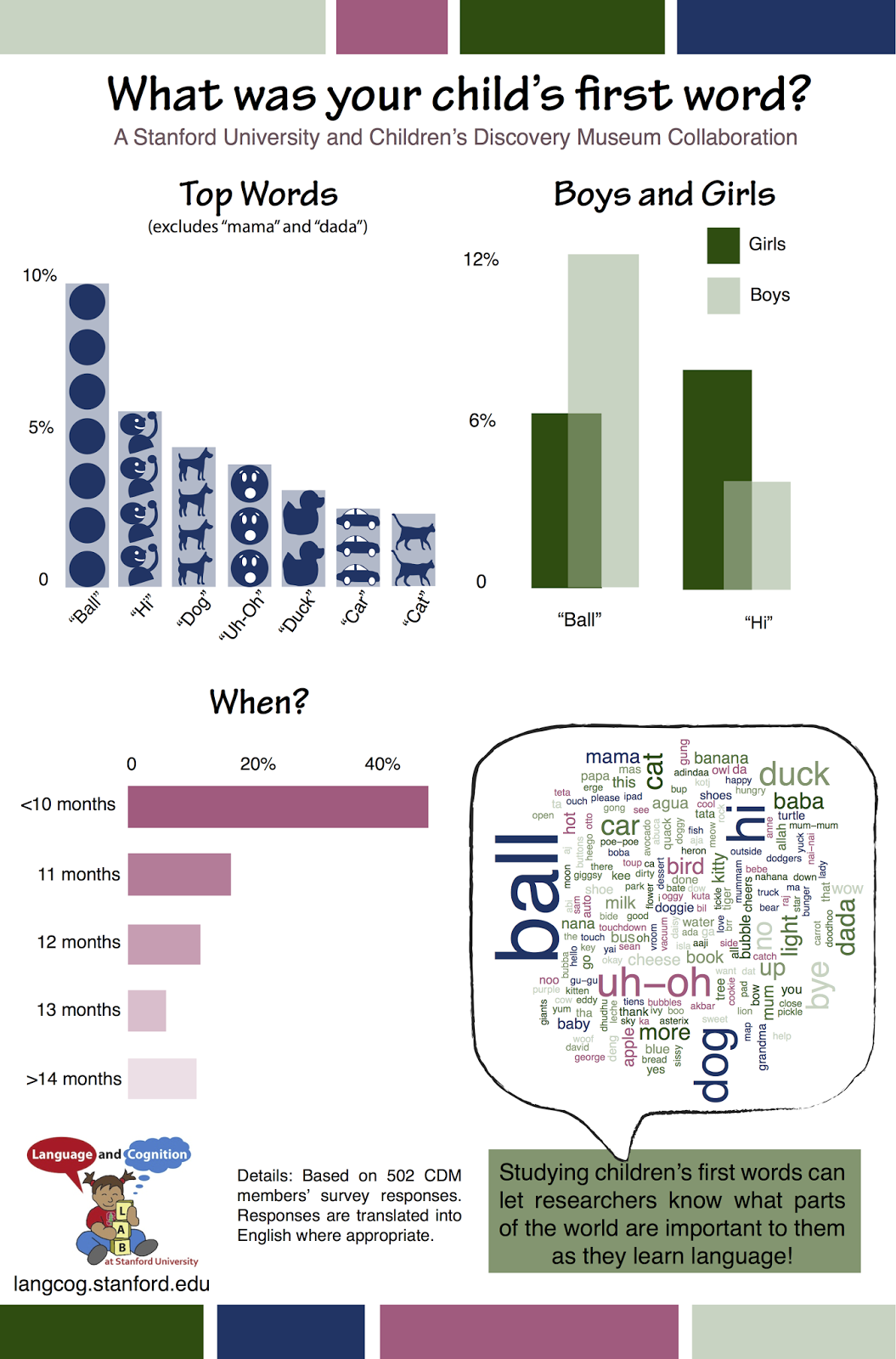
After we got Jonathan's stimulus set, Desmond created a MTurk version of the KTE experiment and collected data in a high-power replication, which reproduced all of their key statistical tests. We were very pleased, and got together with Jonathan to plan followup experiments. Our hope was to use this very cool paradigm to test all kinds of subtleties about belief representation, like how detailed the participants' encoding was and whether it respected perceptual access. But then we started taking a closer look at the data we had collected and noticed that the pattern of findings didn't quite make sense. Here is that graph – we scraped the values from KTE's figures and replotted their SEM as 95% CIs:

The obvious thing is the difference in intercept between the two studies, but we actually don't have a lot to say about that – RT calculations depend on when you start the clock, and we don't know when KTE started the clock in their study. We also did our study on the internet, and though you can get reliable RTs online, they may be a bit slower for all kinds of unimportant reasons.
We also saw some worrisome qualitative differences between the two datasets, however. KTE's data look like people are slower when the Smurf thinks the ball is absent AND when they themselves think the ball is absent too. In contrast, we see a crossover interaction – people are slow when they and the Smurf think the thing is absent, but they are
also slow when they and the Smurf think the thing is present. That makes no sense on KTE's account – that should be the fastest condition. What's more, we can't be certain that KTE
wouldn't have seen that result, because their overall effects were so much smaller and their relative precision given those small effects seemed lower.
I won't go through all the ways that we tried to make this crossover interaction go away. Suffice it to say, it was a highly replicable finding, across labs and across all kinds of conditions that shouldn't have produced it. Here's Figure 3 from the paper:
Somewhere during this process, we joined forces with Rebecca, and found that they saw the crossover as well (panels marked "1c: Lab" and "2b: Lab 2AFC"). So Desmond and Jonathan then led the effort to figure out the source of the crossover.
Here's what they found. The KTE paradigm includes an "attention check" in which participants have to respond that they saw the Smurf leave the room. But the timing of this attention check is not the same across belief conditions – in other words, it's confounded with condition. And the timing of the attention check actually looks a lot like the crossover we observed: In the two conditions where we observed the slowest RTs, the attention check is closer in time to the actual decision that participants have to make.
There's an old literature showing that making two reaction time decisions right after one another makes the second one slower. We think this is exactly what's going on in KTE's paper, and we believe our experiments demonstrate it pretty clearly. When we don't have an attention check, we don't see the crossover; when we do have the check, but it doesn't have a person in it at all (just a lightbulb), we still see the crossover; and when we control the timing of the check, we eliminate the crossover again.
Across studies, we were able to produce a double dissociation between belief condition and the attention check. To my mind, this dissociation provides strong evidence that the attention check – and not the agent's belief – is responsible for the findings that KTE observed. In fact, KTE and collaborators actually also see a flat RT pattern
in a recent article that didn't use the attention check (check their SI for the behavioral results)! So their results are congruent with our own – this also partially mitigates our concern about the stimulus issue. In sum, we don't think the KTE paradigm provides any evidence on the presence of automatic theory of mind.
Thoughts on this process.
1. Several people who are critical of the replication movement more generally (e.g.
Jason Mitchell,
Tim Wilson) have suggested that we pursue "positive replications," where we identify moderator variables that control the effects of interest. That's what we did here. We "debugged" the experiment – figured out exactly what went wrong and led to the observed result. Of course, the attention check wasn't a theoretically-interesting moderator, but I think we did exactly what Mitchell and Wilson are talking about.
But I don't think "positive replication" is a sustainable strategy more generally. KTE's original N=24 experiment took us 11 experiments and almost 900 participants to "replicate positively," though we knew much sooner that it wouldn't be the paradigm we'd use for future investigations (what we might have learned from the first direct replication, given that the RTs didn't conform to the theoretical predictions).
The burden in science can't fall this hard on the replicators all the time. Our work here was even a success by my standards, in the sense that we eventually figured out what was going on! There are other experiments I've worked on, both replications and original studies, where I've never figured out what the problem was, even though I knew there was a problem. So we need to acknowledge that replication can establish – at least – that some findings are not robust enough to build on, or do not reflect the claimed process, without ignoring the data until the replicators figure out exactly what is going on.
2. The replication movement has focused too much for my taste on binary effect size estimation or hypothesis testing, rather than model- or theory-based analysis. There's been lots of talk about replication as a project of figuring out if the original statistical test is significant, or if the effect size is comparable. That's not what this project was about – I should stress that KTE's original paradigm did prove replicable. All of the original statistical tests were statistically significant on basically every replication we did. The problem was that the
overall pattern of data still wasn't consistent with the proposed theory. And that's really what the science was about.
This sequence of experiments was actually a bit of a
reductio ad absurdum with respect to null-hypothesis statistical testing more generally. Our paper includes 11 separate samples. Despite having planned to have >80% power for all of the tests we did, the sheer scope means that a good number of them would not come out statistically significant, just by chance. So we were in a bit of a quandary – we had predictions that "weren't satisfied" in individual experiments, but we'd strongly expect that to be the case just by chance! (The probability of 11 statistical tests, each with 80% power, all coming out significant is less than .1).
So rather than looking at whether all the
p-values were independently below .05, we decided to aggregate the RT effect size on the key effect using meta-analysis. This analysis allowed us to see which account best predicted the RT differences across experiments and conditions. We aggregated the RT coefficients for the crossover interaction (panel A below) and the RT differences for the key contrast in the automatic theory of mind hypothesis (panel B below). You can see the result here:
The attention check hypothesis clearly differentiates between conditions where we see a big crossover effect and conditions where we don't. In contrast, the automatic theory of mind hypothesis doesn't really differentiate the experiments, and the meta-analytic effect estimate goes in the wrong direction. So the combined evidence across our studies supports the attention check being the source of the RT effect.
Although this analysis isn't full
Bayesian model comparison, it's a reasonable method for doing something similar in spirit – comparing the explanatory value of two different hypotheses. Overall, this experience has shifted me much more strongly to more model-driven analyses for large study sets, since individual statistical tests are guaranteed to fail in the limit – and that limit is much closer than I expected.
3. Where does this leave theory of mind, and the infant literature in particular? As we are at pains to say in our paper, we don't know. KTE's infant experiments didn't have the particular problem we describe here, and so they may still reflect automatic belief encoding. On the other hand, the experience of investigating this paradigm has made me much more sensitive to the issues that come up when you try to create complex psychological state manipulations while holding constant participants' low-level perceptual experience. It's hard!
Cecilia Hayes has recently written several papers making this same kind of point (
here and
here). So I am uncertain about this question more generally.
That's a low note to end on, but this experience has taught me a tremendous amount about care in task design, the flaws of the general null-hypothesis statistical approach as we get to "slightly larger data" (not "big data" even!) in psychology, and replication more broadly. All of our data, materials, and code – as well as a link to our actual experiments, in case you want to try them out – are
available on github. We'd welcome any feedback; I believe KTE are currently writing a response as well, and we look forward to seeing their views on the issue.
---
(Minor edit: I got Cecilia Heyes' name wrong, thanks to Dale Barr for the correction).

 Cortes Barragan R, & Dweck CS (2014). Rethinking natural altruism: Simple reciprocal interactions trigger children's benevolence. Proceedings of the National Academy of Sciences of the United States of America, 111 (48), 17071-4 PMID: 25404334
Cortes Barragan R, & Dweck CS (2014). Rethinking natural altruism: Simple reciprocal interactions trigger children's benevolence. Proceedings of the National Academy of Sciences of the United States of America, 111 (48), 17071-4 PMID: 25404334