Every year, one of the trickiest concepts for me to teach in my experimental methods course is the difference between experimental confounds and covariates. Although this distinction seems simple, it's pretty deeply related to the definition of what an experiment is and why experiments lead to good causal inferences. It's also caught up in a number of methodological problems that come up again and again in my class. This post is my attempt to explain the distinction and how it relates to different problems and cultural practices in psychology.
Throughout this post, I'll use a silly example. My first year of graduate school, I got distracted from my actual research by the hypothesis that listening to music with lyrics decreased my ability to write papers for my classes. I'll call this the "Bob Dylan" hypothesis, since I was listening to a lot of Dylan at the time. Let's represent this by the following causal diagram.

Observational Studies and Experiments
Suppose we did an observational study where we measured each of these variables in a large population. Assume we came up with some way to sample people's writing, get a measure of whether they either were or weren't listening to lyric-heavy music at the time, and assess the writing sample's quality. We might find that Y was correlated with X, but in a surprising direction: listening to Dylan would be related to better writing.
Can we make a causal inference in this case? If so, we could get rich promoting a Dylan-based writing intervention. Unfortunately, we can't – correlation doesn't equal causation here, because there is (at least one) confounding third variable: age (Z). Age is positively related to both Dylan listening and writing skill in our population of interest. Older people tend to be good writers and also tend to be more into folk rockers; I'm not even going to put a question mark on this edge because I'm pretty sure this is true.

To get gold-standard evidence about causality, we need to do an experiment. (We won't discuss statistical techniques for inferring causality, which can be useful but don't give you gold standard evidence anyway; review here).
Experiments are when we intervene on the world and measure the consequences. Here, this means forcing some people to listen to Dylan. In the language of graphical models, if we control the Dylan listening, that means that variable X is causally exogenous. (Exogenous means that it's not caused by anything else in the system). We "snipped" the causal link between age and Dylan listening.

So now we can "wiggle" the Dylan listening variable – change it experimentally – and see if we detect any changes in writing skill. We do this by randomly assigning individuals to listen to Dylan or not and then measuring writing during the assigned listening (or non-listening) period. This is a "between-subjects" design. We can use our randomized experiment to get a measure of the average treatment effect of Dylan, the size of the causal effect of the intervention on the outcome. In this simple experiment, the ATE is estimated by the regression Y ~ X (for ease of exposition, I'm not going to discuss so-called mixed models, which model variation across subjects and/or experimental items). That's the elegant logic of randomized experiments: the difference between condition gives you the average effect.
Confounds
Let's consider an alternate experiment now. Suppose we did the same basic procedure, but now with a "within-subjects" design where participants do both the Dylan treatment and the control, in that order. This experiment is flawed, of course. If you observe a Dylan effect, you can't rule out the idea that participants got tired and wrote worse in the control condition because it always came second.
Order (Dylan first vs. control first; notated X') is an experimental confound: a variable that is created in the course of the experiment that is both causally related to the predictor and potentially also related to the outcome. Here's how the causal model now looks:
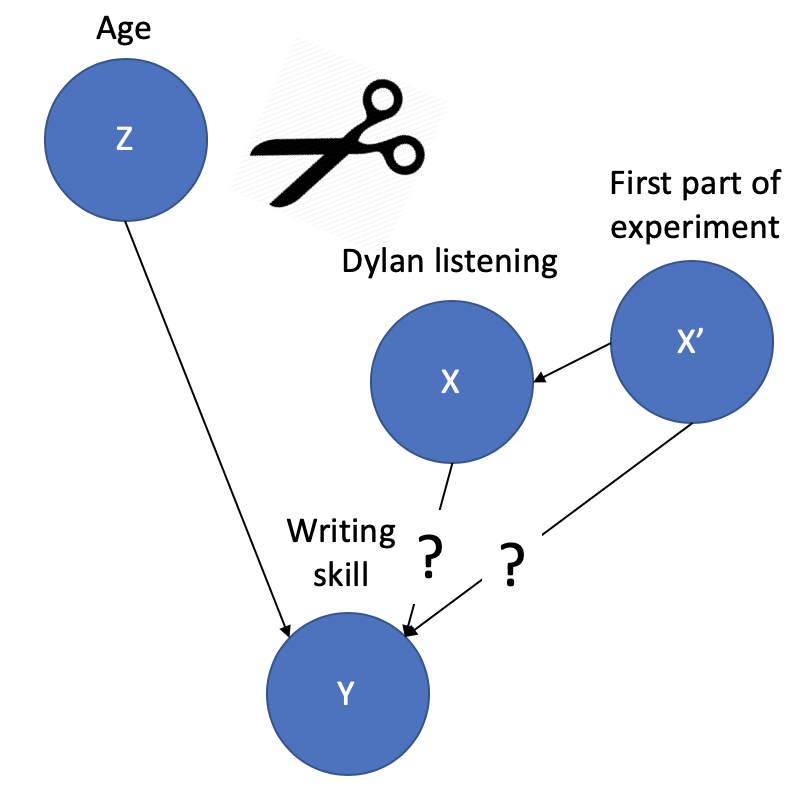
We've reconstructed the same kind of confounding relationship we had with age, where we had a variable (X') that was correlated both with our predictor (X) and our outcome (Y)! So...
What should we do with our experimental confounds?
Option 1. Randomize. Increasingly, this is my go-to method for dealing with any confound. Is the correct answer on my survey confounded with response side? Randomize what side the response shows up on! Is order confounded with condition? Randomize the order you present in! Randomization is much easier now that we program many of our experiments using software like Qualtrics or code them from scratch in JavaScript.
The only time you really get in trouble with randomization is when you have a large number of options, a small number of participants, or some combination of the two. In this case, you can end up with unbalanced levels of the randomized factors (for example, ten answers on the right side and two on the left). Averaging across many experiments, this lack of balance will come out in the wash. But in a single experiment, it can really mess up your data – especially if your participants notice and start choosing one side more than the other because it's right more often. For that reason, when balance is critical, you want option 2.
Option 2. Counterbalance. If you think a particular confound might have a significant effect on your measure, balancing it across participants and across trials is a very safe choice. That way, you are guaranteed to have no effect of the confound on your average effect. In a simple counterbalance of order for our Dylan experiment, we manipulate condition order between subjects. Some participants hear Dylan first and others hear Dylan second. Although technically we might call order a second "factor" in the experiment, in practice it's really just a nuisance variable, so we don't talk about it as a factor and we often don't analyze it (but see Option 3 below).
In the causal language we have been using, counterbalancing allows us to snip out the causal dependency between order and Dylan. Now they are unconfounded (uncorrelated) with one another. We've "solved" a confound in our experimental design. Here's the picture:

Counterbalancing doesn't always work, though. It gets trickier when you have too many levels on a variable (too many Dylan songs!) or multiple confounding variables. For example, if you have lots of different nuisance variables – say, condition order, what writing prompt you use for each order, which Dylan song you play – it may not be possible to do a fully-crossed counterbalance so that all combinations of these factors are seen by equal numbers of participants. In these kinds of cases, you may have to rely on partial counterbalancing schemes or latin squares designs, or you may have to fall back on randomization.
Option 3. Do Options 1 and 2 and then model the variation. This option was never part of my training, but it's an interesting third option that I'm increasingly considering.** That is, we are often faced with the choice between A) a noisy between-participants design and B) a lower-noise within-participants design that nevertheless adds noise back in via some obvious order effect that you have to randomize or counterbalance. In a recent talk by Andrew Gelman, he suggested that we try to model these as covariates, to reduce noise. This seems like a pretty interesting suggestion, especially if the correlation between them and the outcome is substantial.***
Covariates
Going back to our example, now we have two variables – age and order – that are no longer confounded with our primary relationship of interest (i.e., Dylan and writing). But they may still be related to our outcome measure. Here's what the picture looks like, repeated from above.
Even if they are not confounding our experimental manipulation, age and experimental condition order may still be correlated with our outcome measure, writing skill. How does this work? Well, the average treatment effect of Dylan on writing is still given by the regression Y ~ X. But we also know that there is some variance in Y that is due to X' and Z.
That's because age and order are covariates: they may – by virtue of their potential causal links with the outcome variable – have some correlation with outcomes, even in a case where the predictor is experimentally manipulated. This should be intuitive for the external (age) covariate, but it's true for both: they may account for variance in Y over and above that controlled by the experimental manipulation of X.
What should we do about our covariates?
Option 1. Nothing! We are totally safe in ignoring all of our covariates, regressing Y on X and treating the estimate as an unbiased estimate of the the effect (the ATE). This is why randomization is awesome. We are guaranteed that, in the limit of many different experiments, even though people with different ages will be in the different Dylan conditions, this source of variation will be averaged out.
The first fallacy of covariates is that, because you have a known covariate, you have to adjust for it. Not true. You can just ignore it and your estimate of the ATE is unbiased. This is the norm in cognitive psychology, for example: variation between individuals is treated as noise and averaged out. Of course, there are weaknesses in this strategy – you will not learn about the relationship of your treatment to those covariates! – but it is sound.
Option 2. If you have a small handful of covariates that you believe are meaningfully related to the outcome, you can plan in advance to adjust for them in your regression. In our Dylan example, this would be a pre-registered plan to add Z as a predictor: Y ~ X + Z. If age (Z) is highly correlated with writing ability (Y), then this will give us a more precise estimate of the ATE, while remaining unbiased.
When should we do this? Well, it turns out that you need a pretty strong correlation to make a big difference. There's some nice code to simulate the effects of covariate adjustment on precision in this useful blogpost on covariate adjustment; I lightly adapted it. Here's the result:

Considering these numbers in light of our Dylan study, I would bet that age and writing skill are not correlated with writing skill > .8 (unless we're looking at ages from kindergarten to college!). I would guess that in an adult population this correlation would be much, much lower. So maybe it's not worth controlling for age in our analyses.
And the same is probably true for order, our other covariate. Although perhaps we do think that our order has a strong correlation with our skill measure. For example, maybe our experiment is long and there are big fatigue effects. In that case, we would want to condition.
So these are are options: if the covariate is known to be very strong, we can condition. Otherwise we should probably not worry about it.
What shouldn't we do with our covariates?
Don't condition on lots and lots of covariates because you think they are theoretically important. There are lots of things that people do with covariates that they shouldn't be doing. My personal hunch is that this is because a lot of researchers think that covariates (especially demographic ones like age, gender, socioeconomic status, race, ethnicity, etc.) are important. That's true: these are important variables. But that doesn't mean you need to control for them in every regression. This leads us to the second fallacy.
The second fallacy of covariates is that, because you think covariates are in general meaningful, it is not harmful to control for them in your regression model. In fact, if you control for meaningless covariates in a standard regression model, you will on average reduce your ability to see differences in your treatment effect. Just by chance your noise covariates will "soak up" variation in the response, leaving less to be accounted for by the true treatment effect! Even if you strongly suspect something is a covariate, you should be careful before throwing it into your regression model.
Don't condition on covariates because your groups are unbalanced. People often talk about "unhappy randomization": you randomize adults to the different Dylan groups, for example, but then it turns out the mean age is a bit different between groups. Then you do a t-test or some other statistical test and find out that you actually have a significant age difference. But this makes no sense: because you randomized, you know that the difference in ages occurred by chance, so why are you using a t-test to test if the variation is due to chance? In addition, if your covariate isn't highly correlated with the outcome, this difference won't matter (see above). Finally, if you adjust for this covariate because of such a statistical test, you can actually end up biasing estimates of the ATE across the literature. Here's a really useful blogpost from the Worldbank that has more details on why you shouldn't follow this practice.
Don't condition on covariates post-hoc. The previous example is a special case of a general practice that you shouldn't follow. Don't look at your data and then decide to control for covariates! Conditioning on covariates based on your data is an extremely common route for p-hacking; in fact, it's so common that it shows up in Simmons, Nelson, & Simonsohn's (2011) instant classic False Positive Psychology paper as one of the key ingredients of analytic flexibility. Data-dependent selection of covariates is a quick route to false positive findings that will be less likely to be replicable in independent samples.
Don't condition on a post-treatment variable. As we discussed above, there are some reasons to condition on highly-correlated covariates in general. But there's an exception to this rule. There are some variables that are never OK to condition on – in particular, any variable that is collected after treatment. For example, we might think that another good covariate would be someone's enjoyment of Bob Dylan. So, after the writing measurements are done, we do a Dylan Appreciation Questionnaire (DAQ). The problem is, imagine that having a bad experience writing while listening to Dylan might actually change your DAQ score. So then people in the Dylan condition would have lower DAQ on average. If we control for DAQ in our regression (Y ~ X + DAQ), we then distort our estimate of the effects of Dylan. Because DAQ and X (Dylan condition) are correlated, DAQ will end up soaking up some variance that is actually due to condition. This is bad news. Here's a nice paper that explains this issue in more detail.
Don't condition on a collider. This issue is a little bit off-topic for the current post, since it's primarily an issue in observational designs, but here's a really good blogpost about it.
Conclusions
Covariates and confounds are some of the most basic concepts underlying experimental design and analysis in psychology, yet they are surprisingly complicated to explain. Often the issues seem clear until it comes time to do the data analysis, at which point different assumptions lead to different default analytic strategies. I'm especially concerned that these strategies vary by culture, for example with some psychologists always conditioning on confounders, and others never doing so. (We haven't even talked about mediation and moderation!). Hopefully this post has been useful in using the vocabulary of causal models to explain some of these issues.
---
* The definitive resource on causal graphical models is Pearl (2009). It's not easy going, but it's very important stuff. Even just starting to read it will strengthen your methods/stats muscles.
** Importantly, it's a lot like adding random effects to your model – you model sources of structure in your data so that you can better estimate the particular effects of interest.
*** The advice not to model covariates that aren't very correlated with your outcome is very frequentist, with the idea being that you lose power when you condition on too many things. In contrast, Gelman & Hill (2006) give more Bayesian advice: if you think a variable matters to your outcome, keep it in the model. This advice is consistent with the idea of modeling experimental covariates, even if they don't have a big correlation with the outcome. In the Bayesian framework, including this extra information should (maybe only marginally) improve your precision but you aren't "spending degrees of freedom" in the same way.