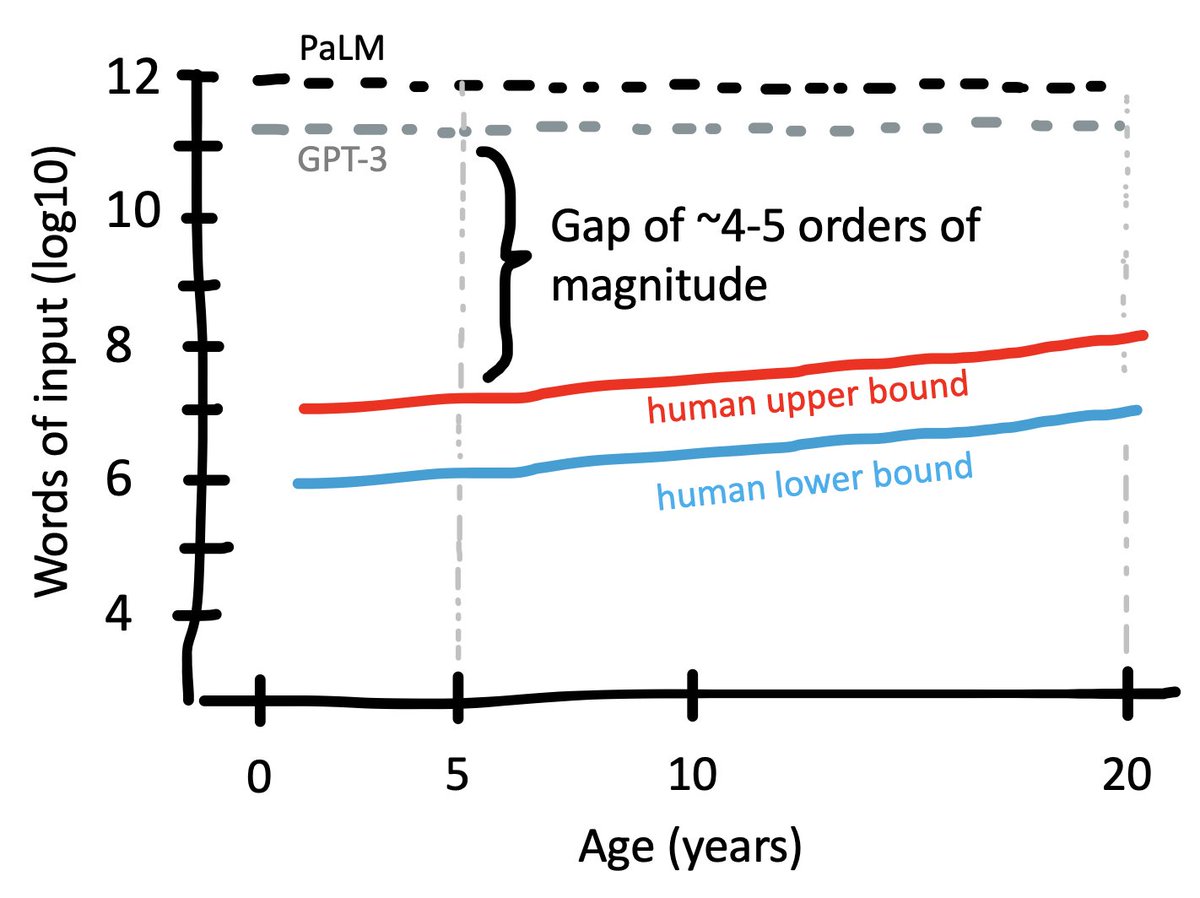
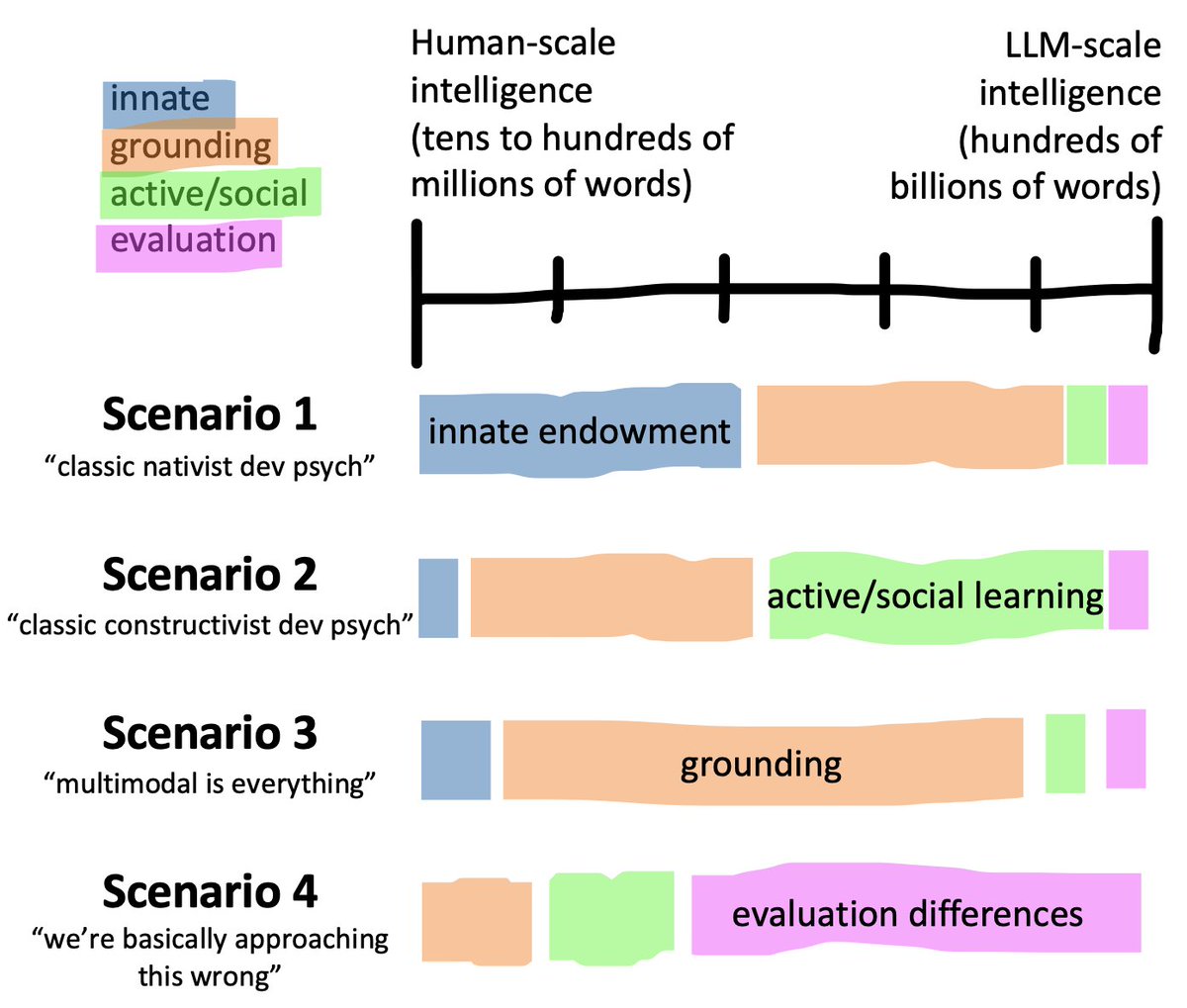
I'm normally an avid fiction reader, but this summer I've been on a non-fiction kick. I just finished listening to Nicole Rust's new book, Elusive Cures. The premise of the book is the simple, important question: why haven't we made more progress on understanding brain disorders using basic neuroscience? Rust's argument is that the kind of "domino chain" causal model that we use to understand many neural systems is simply mismatched to the nature of how complex systems work. Rust is a cognitive neuroscientist who is known for her work on vision and memory, but she does not lean on these areas in the book, instead broadly surveying the neuroscience of disorders including Alzheimer's, Parkinson's, and depression.
Although I'm mostly a cognitive scientist these days, Rust's description of the forward causal model for neuroscience immediately felt familiar from from my grad school neuroscience training. These kinds of causal systems are the ones we've made the most progress on in cognition as well: we have pretty strong models of how visual object recognition, reading, and language processing unfold in time. In contrast, processes that unfold interactively over time, such as mood, are much harder to understand this way.
I have often been skeptical of the application of complex dynamical systems theory to cognition, though Rick Dale's nice intro for the Open Encyclopedia of Cognitive Science did win me over somewhat. I agree that cognition is a complex dynamical system, but in practice such formalisms can often feel unconstrained. Many researchers using dynamical systems theories don't – for whatever reason – engage in the kind of systematic model comparison and evaluation that I believe is critical for cognitive modeling.
I heard that same kind of skepticism in Rust's own writing, which made it even more compelling when she made the case for the critical importance of understanding the brain as a complex dynamical system. Her discussion of the role of homeostasis in brain systems in particular was inspiring. It made me wonder why we don't apply the concept of homeostasis more to reason about social systems as well – for example, how communities maintain their educational standards in the face of policy changes or interventions. It's always a pleasure when a book sparks this kind of reflection.
In sum, I strongly recommend Elusive Cures. I found it thought-provoking and broad, with good descriptions of both individual research findings and sweeping trends. The book feels like the rare "popular" book that also effectively makes a forceful scientific argument.