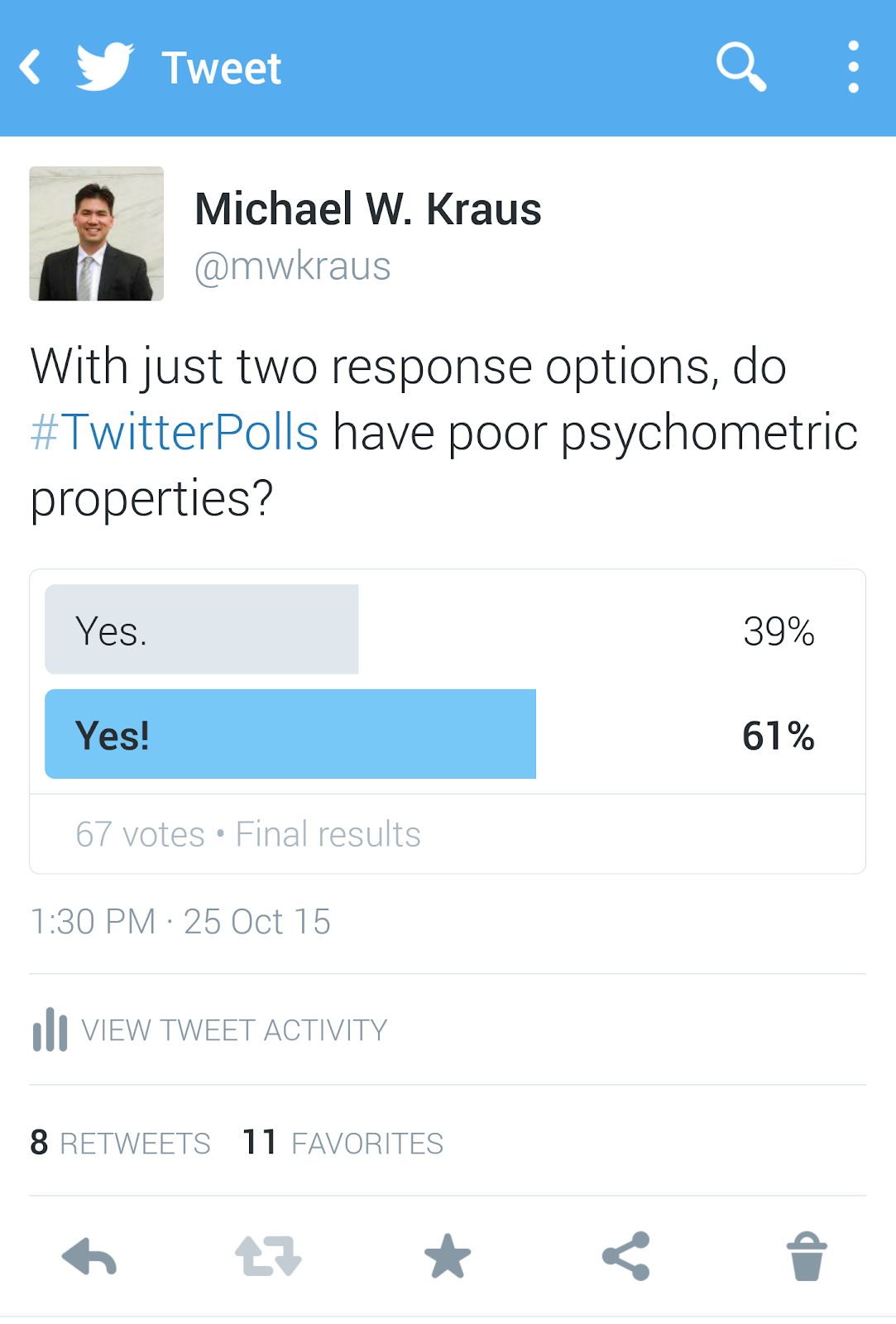
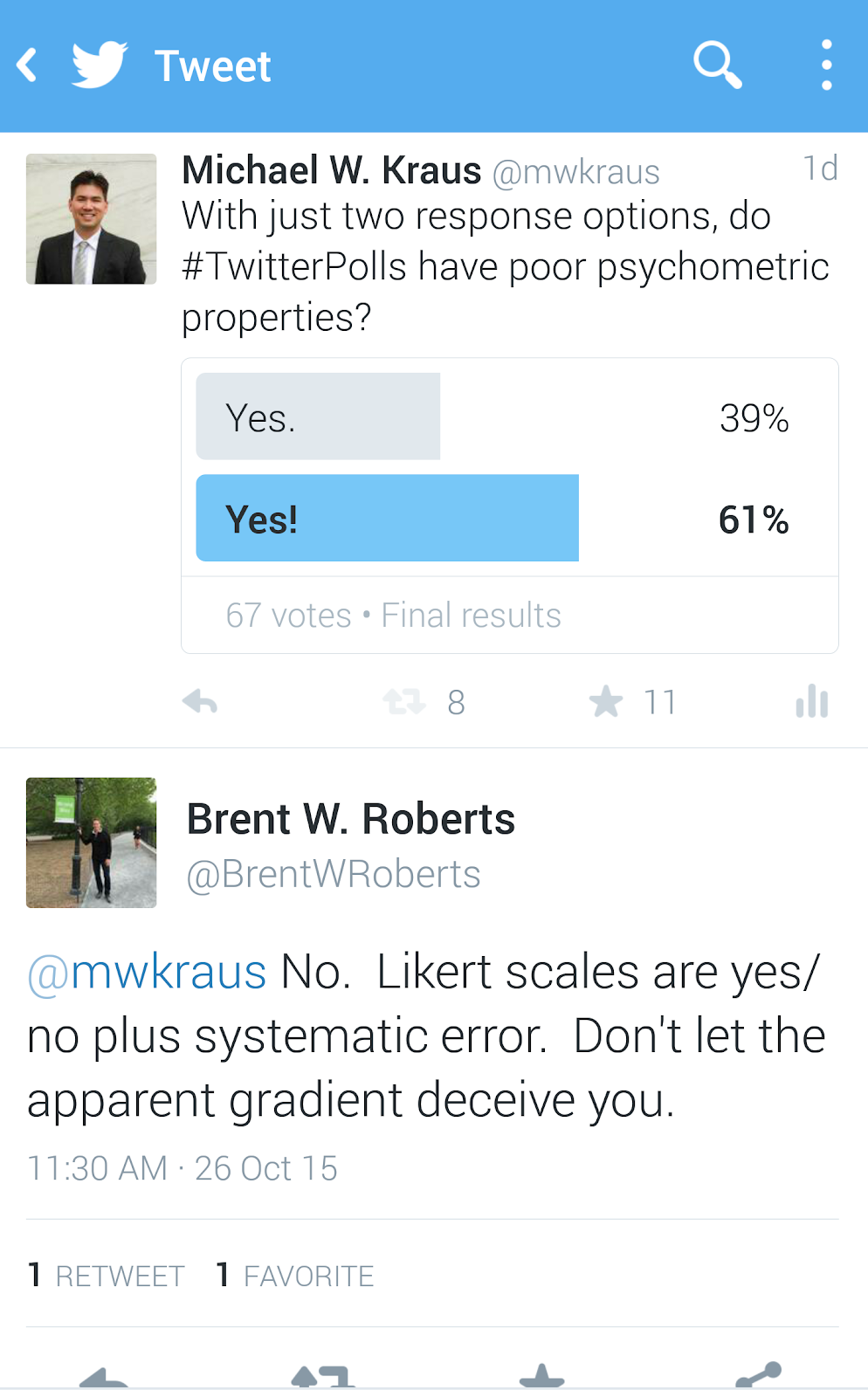
The
National Children's Study was a 100,000-child longitudinal study that would have tracked a cohort of children from birth to age 21, measuring environmental, family, genetic, and cognitive aspects of development at an unprecedented scale. Unfortunately, last year the NIH Director decided to
shut the study down, following a
highly critical report from the National Academy of Sciences that criticized a number of aspects of the study including its leadership and its sampling plan.
I got involved in the NCS about a year ago, when I was asked to be a part of the Cognitive Health team. Participating in the team has been an extremely positive experience, as I've had a chance to work with a great group of developmental researchers. We've met weekly for the past year, first to create plans for the cognitive portions of NCS, and later – after the study was cancelled – to discuss possible byproducts of the group's work. (Full disclosure: I am still a contractor for NCS and will be until the final windup is completed).
According to recent reports, though, NCS
may be restarted by an act of Congress. As originally conceived, the study served a very valuable purpose: creating a sample large enough and diverse enough to allow analyses of rare outcomes, even for parts of the population that are often underrepresented in other cohorts.
Other countries clearly think this is a good idea.
According to one proposal, though, recruitment in the new study might piggyback on other ongoing studies. I'm not sure how this could work, given that different studies would likely have radically different measures, ages, and recruitment strategies. Even if some of these choices were coordinated, differences in implementation of the studies would make inferences from the data much more problematic.
I would love to see the original NCS vision carried to fruition. But even based on my limited perspective, I also understand why the project was extremely slow to start and ran into substantial cost obstacles. Creating such a massive design inevitably runs into problems of interlocking constraints, where decisions about recruitment depend on decisions about design and vice versa. Converging on the right measures is such a difficult process that by the time decisions are made, they are already out of date (a critique leveled also by the NAS report).
If the NCS is restarted, it will need a faster and cheaper planning process to have a chance of going forward to data collection. Here's my proposal:
the NCS needs to work as if it's building a piece of software, not planning a conference. If you're planning a conference, you need to have stakeholders gradually reach consensus on details like the location, the program, and the events, before a single event occurs on a fixed timeline. But if you're building a software application, you need to respond to the constraints of your platform, adapt to your shifting user base, pilot test quickly and iteratively, and make sure that everything works before you release to market. This kind of agile optimization was missing from the previous iteration of the study. Here are three specific suggestions.
1. Iterative piloting.
Nothing reveals the weaknesses of a study design like putting it into practice. In a longitudinal study, the adoption of a bad measure, bad data storage platform, or bad sampling decision early on in the study will dramatically reduce the value of the subsequent data. It's a terrible feeling to collect data on a measure, knowing that the earlier baselines were flawed and the longitudinal analysis will be compromised.
The original NCS included a vanguard cohort of about 5,000 participants, mostly to test the recruitment strategy. (In fact, the costs of the vanguard study may have contributed to the cancelation of the main strategy). But one pilot program is not enough. All aspects of the program need to be piloted, so that the design can be adapted to the realities of the situation. From the length of the individual sessions, to the reliability of the measures and the retention rate across different populations, critical parts of the study all need to be tested multiple times before they are adopted.
The revised NCS should create a staged series of pilot samples of gradually increasing size, whose timeline is designed to allow iteration and incorporation of insights from previous samples. For example, if NCS v2 launches in 2022, then create cohorts of 100, 200, 1000, and 2000 to launch in 2018 – 21, respectively. Make the first samples longitudinal to test dropout (so the sampling design can be adjusted in the main study), and make the last sample cross-sectional so as to pilot test the precise measures that are planned for every age visit. Make it a rule: If
any measure or decision is adopted in the final sample, there must be data on its reliability
in the current study context.
2. Early adoption of precise infrastructure standards.
Here's a basic example of an interlocking constraint satisfaction problem. You need to present measures to parents and collect and store the data resulting from these measures in a coherent data-management framework. But the way you collect the data and the way you store them interact with what the measures are. You can't know exactly how data from a measure (even one as simple as a survey) will look until you know how it will be collected. But you want to design the infrastructure for data collection around the measures that you need.
One way to solve this kind of problem is to iterate gradually into a solution. One committee discusses measures, a second discusses infrastructure. They discuss their needs, then meet, then discuss their needs again. Finally they converge and adopt a shared standard. This model can work well if the target you are optimizing to is static, e.g. if the answer stays the same during your deliberations. The problem is that technical infrastructure doesn't stay the same while you work – the best infrastructure is constantly changing. Good ideas for data management when the NCS began are no longer relevant. But if the infrastructure group is constantly changing the platform, then the folks creating the measures can't ever rely on particular functionality.
Software engineers solve this problem by creating design specifications that are
implementation independent. In other words, everyone knows exactly what they need to deliver and what they can rely on others to deliver (and the under-the-hood details don't matter). Consider an API (application programming interface) for an eye-tracker. The experimenter doesn't know how the eye-tracker measures point of gaze, but she knows that if she calls a particular method, say
getPointOfGaze, she will get back X and Y coordinates, accurate to some known tolerance. On the other end of the abstraction, the eye-tracker manufacturers don't need to know the details of the experiment in order to build the eye-tracker. They just need to
getPointOfGaze quickly and accurately.
In a revised NCS, study architects should publish a technical design specification for all (behavioral) measures that is independent of method of administration. Such standards obviate hiring many layers of contractors to implement each set of measures separately. Instead, a single format conversion step can be engineered. For example, a standard survey XML format would be translated into the appropriate presentation format (whether the survey is presented on the phone, on the computer, or on a tablet or phone). As in many modern
content management systems, the users of a measure could rapidly view and iterate on the precise implementation of the measure, rather than having to work through intermediaries.
A further engineering trick that could be applied to this setup is the use of
automated testing and
test suites. Given a known survey format and a uniform standard, it would be far easier to create automated tools to estimate completion time, to test data storage and integrity, and to search for bugs. Imagine if the NCS looked like an open-source software project, in which each "build" of the study protocol would be forced to pass a set of automated tests prior to piloting...
3. Independence of measure development and measure adoption.
Other people's children are great, but we all love our own the best. That's why we don't review our own papers or hire our own PhD students to be our colleagues. The adoption of measures into a longitudinal study is no different. If we allow the NCS to engage in measure development – creating new ways of measuring a particular environmental, physiological, or psychological construct – rather than simply adopting pre-existing standards, we need to take care that these measures are only adopted if they are the best option for fulfilling the study's goals.
Fix this problem by barring NCS designers from being involved in the creation of measures that are then used in the NCS. If the design committee wants a new measure, they must solicit competitive outside bids to create it and then adopt the version that has the most data supporting it in a direct evaluation. To do otherwise risks the inclusion of measures with insufficient evidence of reliability and validity.
This recommendation is based directly on my own experiences in the Cognitive Health team. Over the course of the last year, I've been very pleased to be able to help this team in the development of a new set of measures for profiling infant cognition. Based on automated eye-tracking methods, these measures have the potential to be a ground-breaking advance in understanding individual differences in cognition during infancy. I'm now quite invested in their success and I hope to continue working on them regardless of the outcome of the NCS study.
That's precisely the problem. I am no longer an objective observer of these measures! Had NCS gone forward I would have pushed for their adoption into the main study, even if the data on their efficacy were much more limited than should be necessary for adoption at a national scale. I'm not suggesting that NCS would adopt a really terrible measure. But given what we know about
motivated cognition and the
sunk cost fallacy, it's very likely that the bar would be lower for adopting an internally-developed measure than an external one.
If the NCS acts as a developer of new measures, there is a temptation to continue working to get the perfect suite of measurements, rather than to stop development and run the study. This is the great being the enemy of the good. If the NCS is a
consumer of others' measures – on some rare occasions, measures that it has commissioned and evaluated – then it can more dispassionately adopt the best available option that fits the constraints of the study.
Conclusions
My own experiences with the NCS – limited as they are – have been nothing but positive. I've gotten to work with some great people, seen the initial development of an exciting new tool, and glimpsed the workings of a much larger project. But as I read about the fate of the study as a whole, I worry that the independence that's made my little part of the project so fun to work on – developing standards, envisioning new measures – is precisely why the project as a whole did not move forward.
What I've suggested here is that a new version of the NCS could benefit from an engineering mindset. Having internal deadlines for pilot launches would constrain planning with interim goals. Adding precise technical specifications and the abstractions necessary to work with them would add certainty to the planning process and eliminate many redundant contractors; for example, our new measures would probably be off the table simply because they wouldn't fit into the existing infrastructure. And an adversarial review of measures would better allow designers to weigh independent evidence for adoption.
In sum: bring back the NCS! But run it like you're building an app: one that has to fulfill a set of functions, yes, but also one that has to scale quickly and cheaply to unprecedented size.
---
Thanks to Steve Reznick, my colleague on the Cognitive Health team, for valuable comments on a previous draft. Views and errors are my own.