(This post is jointly written by the MetaLab team, with contributions from Christina Bergmann, Sho Tsuji, Alex Cristia, and me.)
A typical “ages and stages” ordering. Meta-analysis helps us do better.
Developmental psychologists often make statements of the form “babies do X at age Y.” But these “ages and stages” tidbits sometimes misrepresent a complex and messy research literature. In some cases, dozens of studies test children of different ages using different tasks and then declare success or failure based on a binary p < .05 criterion. Often only a handful of these studies – typically those published earliest or in the most prestigious journals – are used in reviews, textbooks, or summaries for the broader public. In medicine and other fields, it’s long been recognized that we can do better.
Meta-analysis (MA) is a toolkit of techniques for combining information across disparate studies into a single framework so that evidence can be synthesized objectively. The results of each study are transformed into a standardized effect size (like Cohen’s d) and are treated as a single data point for a meta-analysis. Each data point can be weighted to reflect a given study’s precision (which typically depends on sample size). These weighted data points are then combined into a meta-analytic regression to assess the evidential value of a given literature. Follow-up analyses can also look at moderators – factors influencing the overall effect – as well as issues like publication bias or p-hacking.* Developmentalists will often enter participant age as a moderator, since meta-analysis enables us to statistically assess how much effects for a specific ability increase as infants and children develop.
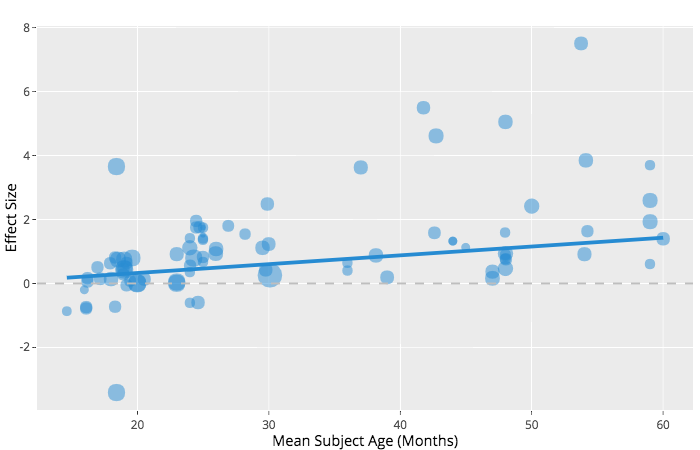
An example age-moderation relationship for studies of mutual exclusivity in early word learning.
Meta-analyses can be immensely informative – yet they are rarely used by researchers. One reason may be because it takes a bit of training to carry them out or even understand them. Additionally, MAs go out of date as new studies are published.
To facilitate developmental researchers’ access to up-to-date meta-analyses, we created MetaLab. MetaLab is a website that compiles MAs of phenomena in developmental psychology. The site has grown over the last two years from just a small handful of MAs to 15 at present, with data from more than 16,000 infants. The data from each MA are stored in a standardized format, allowing them to be downloaded, browsed, and explored using interactive visualizations. Because all analyses are dynamic, curators or interested users can add new data as the literature expands.
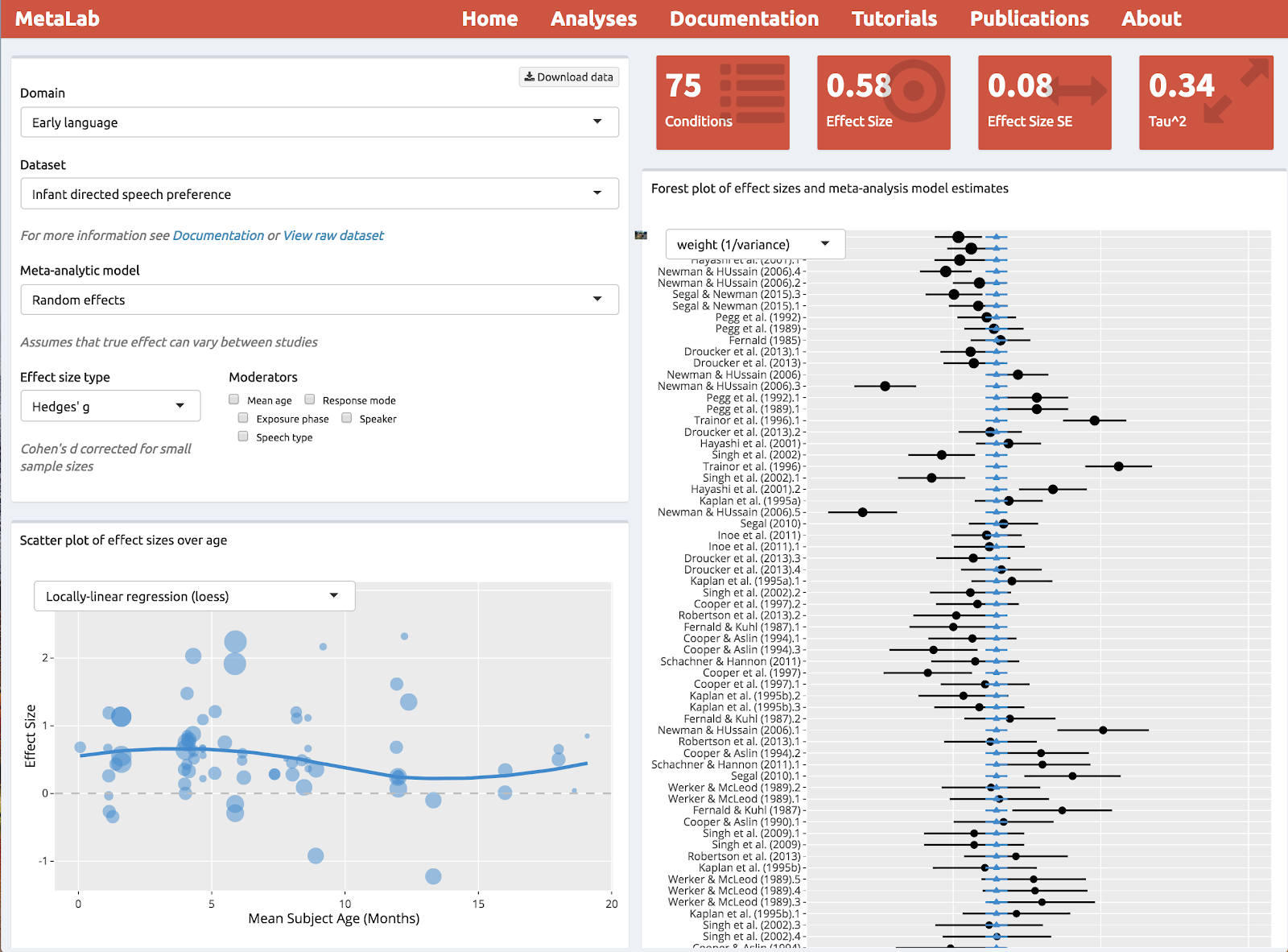
The main visualization app on MetaLab, showing a meta-analysis of infant-directed speech preference. The dataset of interest can be selected in the left upper corner to obtain standard meta-analytic visualizations.
We thought it was time for a refresh for the site this fall, so we are launching a new version today: MetaLab 2.0.** If you have visited MetaLab before, you will notice a lot of changes to the new site. First and foremost, we’ve generalized our approach so that it is not specific to language development in particular but can be used to explore MAs on other topics, which we hope to incorporate as they become available. There are new tutorials, more documentation and explanatory materials (including a youtube video series), and a host of other changes to make the site more intuitive to use.
What can you do with MetaLab? During hypothesis generation, MAs can be a good way to get a comprehensive overview of a literature; we have always noted full references and many MAs even contain unpublished reports that would be difficult to locate otherwise. For instance, about half of the studies in MetaLab’s Sound Symbolism MA are unpublished. Integrating both published and unpublished records, the forthcoming MA by Sho and colleagues suggests that there is overall evidence for early sensitivity to sound symbolism, though it’s weaker than what’s represented in the published literature.
If you are designing a study, MetaLab can help you choose a sample size or stimulus type. For example, Christina's new paper on vowel discrimination uses stimuli that were thought to be appropriately difficult to avoid ceiling or floor effects – which worked! This selection was based on Sho's vowel discrimination MA, which contains both acoustic information and effect sizes.
Even if there is not an MA for your particular phenomenon of interest, you can still learn about the average effect size for related phenomena and methods. And once you’ve finished your study, you can tell us about it so we add it to the appropriate meta-analysis in MetaLab, putting your study in the map of similar studies, and helping other researchers find it.
If you want to learn more, check out our papers (Bergmann et al., in press, Lewis et al., preprint). Bergmann et al. (in press) focuses on study power and method choice, providing instructions how to make a priori sample size decisions to conduct appropriately powered studies. Lewis et al. (preprint) assesses publication bias (spoiler: it's not as bad as we feared, at least in studies of early language) and shows how all MAs on language development together can help us build data-driven theories.
It’s more important than ever to create a cumulative research literature in which our theories rest on the sum of the available evidence and our new work is designed and powered appropriately to make a contribution. MetaLab is designed to help accomplish both of these goals. If you would like to contribute a MA, add an analysis or a datapoint, or simply comment on the site functionality, please reach out to us or add a github issue. And when someone asks you, “when do babies do X?,” you can look for answers based not on a handful of infants but on hundreds or thousands of them.
---
* We’re aware of the issues of meta-analysis with respect to understanding literatures that are deeply scarred by publication bias and p-hacking (e.g., datacolada, Inzlicht et al.). We go into this a bit in our papers on the topic, but basically we think that – although publication bias and QRPs are a problem in our fields as they are everywhere – the literature is not fundamentally corrupted in the same way it is in some subfields.
** With generous support from a SSMART grant from the Berkeley Initiative for Transparency in the Social Sciences (BITSS) and some coding help from AttaliTech,
No comments:
Post a Comment